Which model to use for vision
- YoloV5 ← current
- YoloV8
- YoloV6-v3 at 1280px, GPL-3.0, from source code
- https://github.com/lyuwenyu/RT-DETR with 54.8 mAP
- https://github.com/jozhang97/DETA 63.5 mAP
- MCUNet ? https://github.com/mit-han-lab/mcunet
Zero-shot models seem pretty bad:
- YoloWorld
- OWL + CLIP
- OWL + ViT
- LLaVA 1.5 = detect everything
- NanoOWL github.com/NVIDIA-AI-IOT/nanoowl
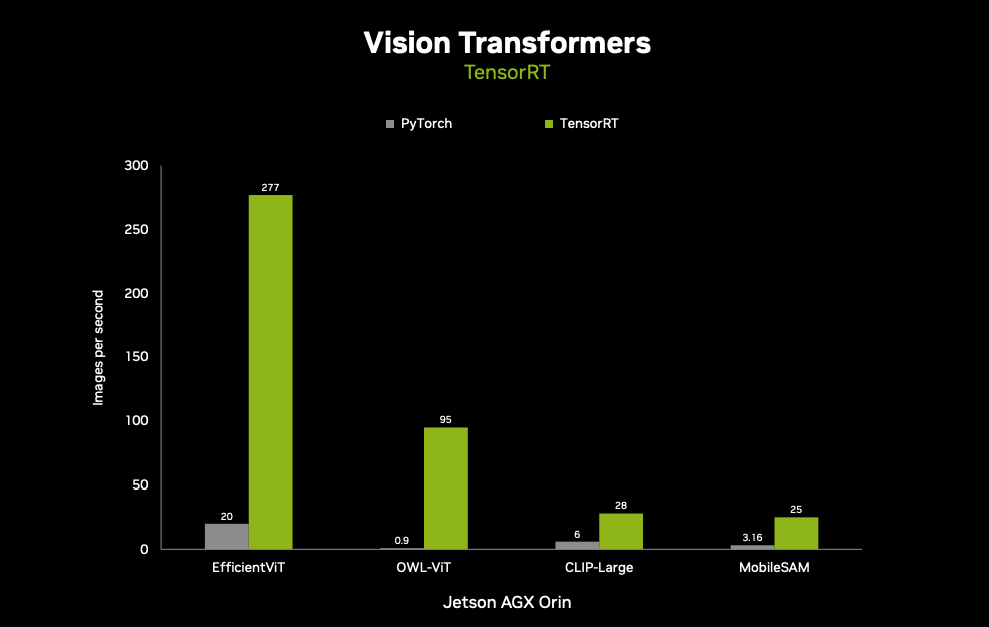
Hardware
- RTX
- A100
Runtimes
- Pytorch
- TensorRT
- ONNX